
7 key roles in a software development team
Here, we cover the 7 key roles you need on your software development team and their responsibilities.
So, you want to build a software product but don’t know much about software development?
Don’t worry, we’ve got you covered.
In this article, we’ll cover everything you need to know about the software development process.
We’ll discuss the key steps in the process, top development methodologies, and essential tools of the trade.
Let’s dive in!
The software development process is the foundation on which successful products are built.
But, around 70% of software projects outright fail.
And 66% of large software development projects run over budget and 33% run over time:
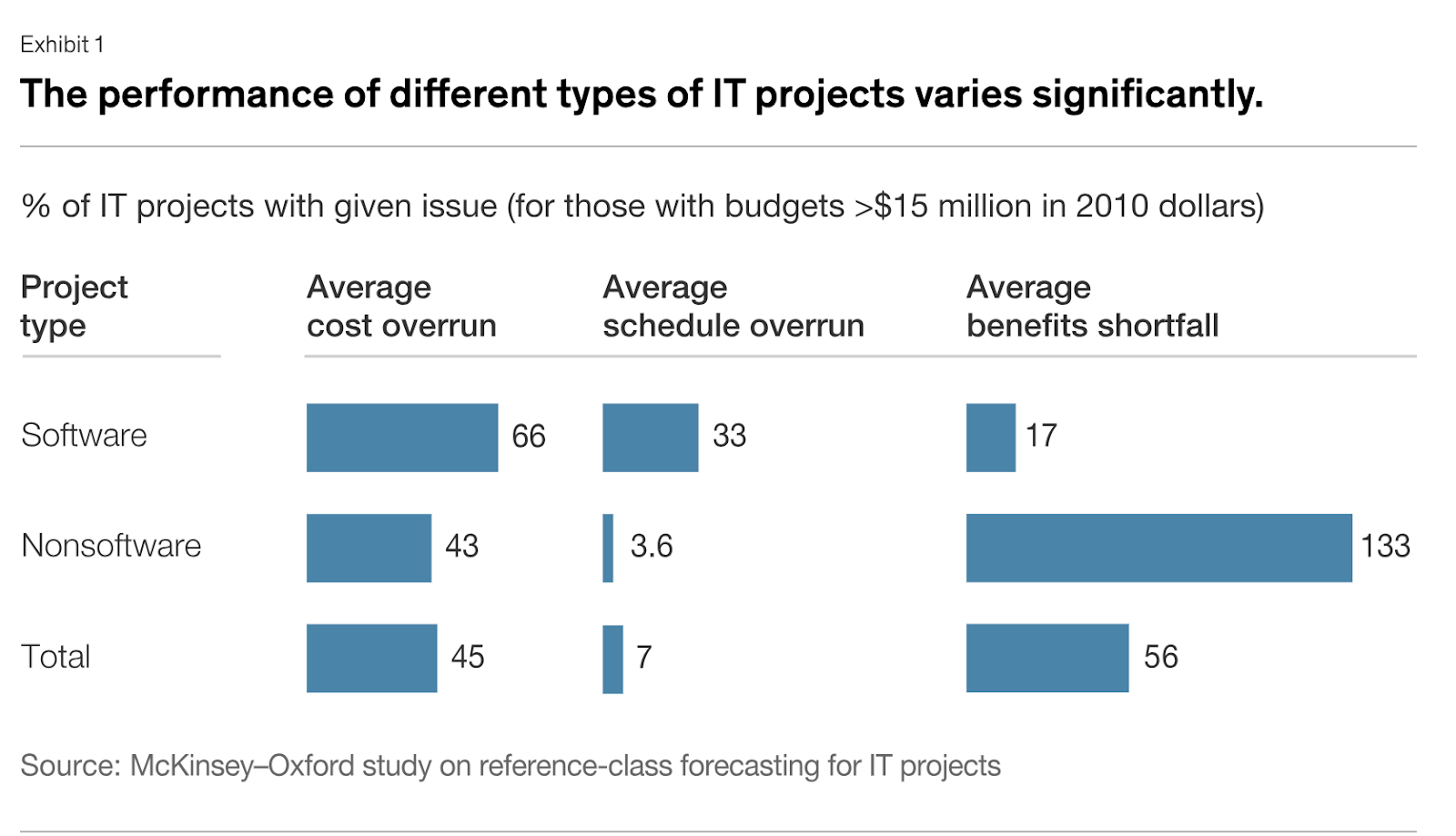
source: McKinsey
Poor development processes are a major reason why these statistics are so dire.
That’s because without a proper development process in place, projects quickly spiral out of control.

You’ll be talking with our technology experts.
Scope creep becomes inevitable, timelines get extended, and costs rise – and that’s just the tip of the iceberg.
And ultimately, this leads to project failure and you losing a lot of money.
But, if you have a well-defined process you will minimize the risk of your project failing – and build better software, too.
Next, we’ll go over the main steps you need to cover in your development process.
Now, we’ll discuss the 7 key steps in the software development process in more detail.
Requirements gathering is the foundation of any successful software project.
The requirements define what your software will do and, more importantly, how it will meet user needs and business goals.
Getting them wrong is a great way to kill your project – 37% of projects fail because of unclear or wrong requirements.
So, for successful development, you need to write a clear and accurate software requirements specification (SRS) document. Here’s what your SRS should include:
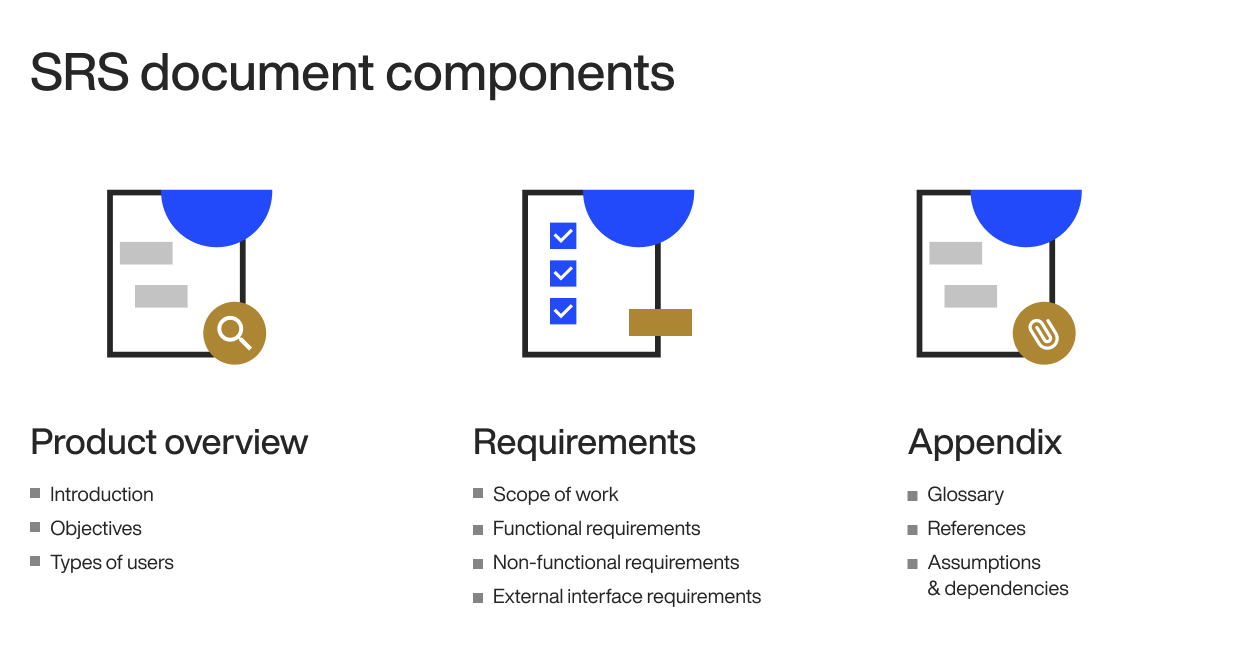
Now, every SRS is unique and yours might not need to have all of these elements.
But, there are 2 non-negotiable elements – your software’s functional and non-functional requirements.
In simple terms, functional requirements cover what your software does while non-functional requirements cover how it does it.
A good, easily understandable SRS document will help you keep development focused and your whole team on the same page.
And that’s key to successful development.
Once you’ve written your SRS, the next key step is planning and roadmapping development.
Here, you turn ideas into actionable steps and make sure that everyone knows what needs to be done, when, and by whom.
Without a well-thought-out plan, even the best ideas will fall apart – a strong roadmap will give your project structure and clarity.
So, how do you get it right?
The key is breaking down the project into manageable stages and:
Your roadmap serves as a visual guide to your project’s phases and contains all of these elements.
Here’s what a typical project roadmap looks like:
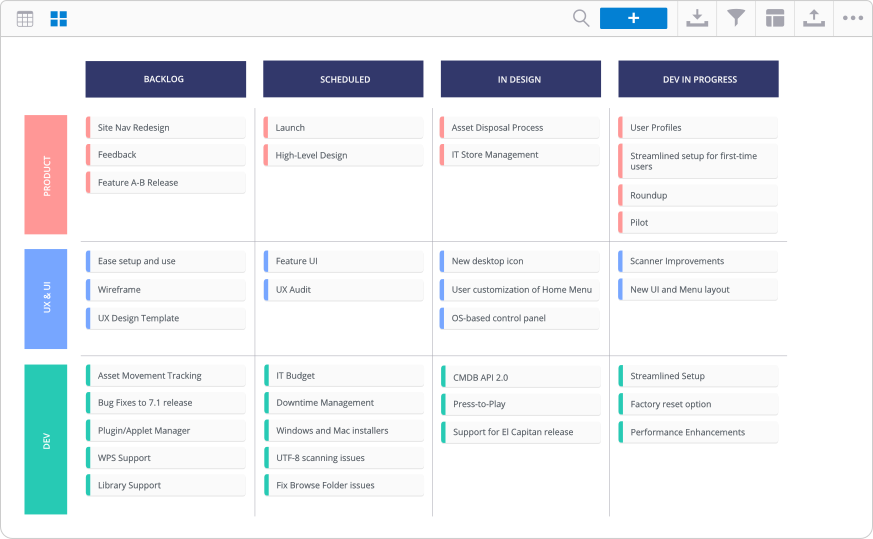
source: Roadmunk
A clear and focused roadmap will help you keep development on track and allow stakeholders to easily track progress.
But, keep in mind that roadmaps aren’t just about setting dates – they’re about creating a clear vision for the entire project.
They give the whole team a clear path to follow and help manage expectations.
And that’s key if you want development done on time and within budget.
A well-executed design is key to the success of any software product.
But, design is about more than just aesthetics. Like Steve Jobs once said:
Design is not just what it looks like and feels like. Design is how it works.
Steve Jobs, Apple co-founder and CEO
And that’s why there are several types of design you need to do during development, like:
Design is about taking the abstract ideas from the planning phase and turning them into a tangible product.
A good design will help you build a usable product with a great user experience (UX).
And investing in UX is one of the best decisions you can make – or every $1 you invest, you get $100 in return, for an ROI of 9,900%!
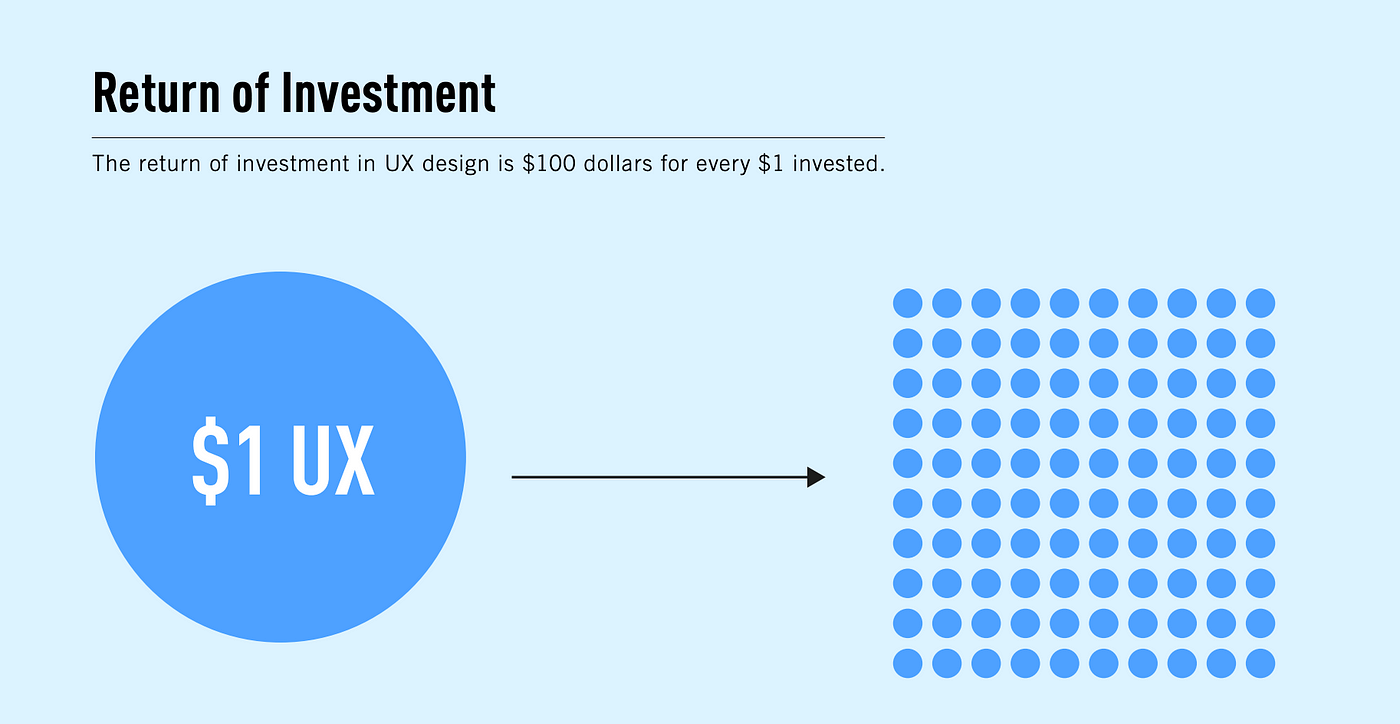
source: UX Collective
So, how do you nail the UX/UI design process?
Usually, it’s done in 5 stages:
Out of all of these, user research is the most important.
You’ll get a clear understanding of user needs and create a design that actually meets those needs.
And that’s key to success.
Coding and development are where the magic happens.
Here, your team takes your requirements and design and turns them into working software.
And if you’ve nailed the previous steps, you shouldn’t have (too) many problems in this stage.
But, your development team still needs to follow best practices like:
Let’s zoom in one of these – writing clean code.
Here’s an example of PHP code before and after it’s been cleaned up:
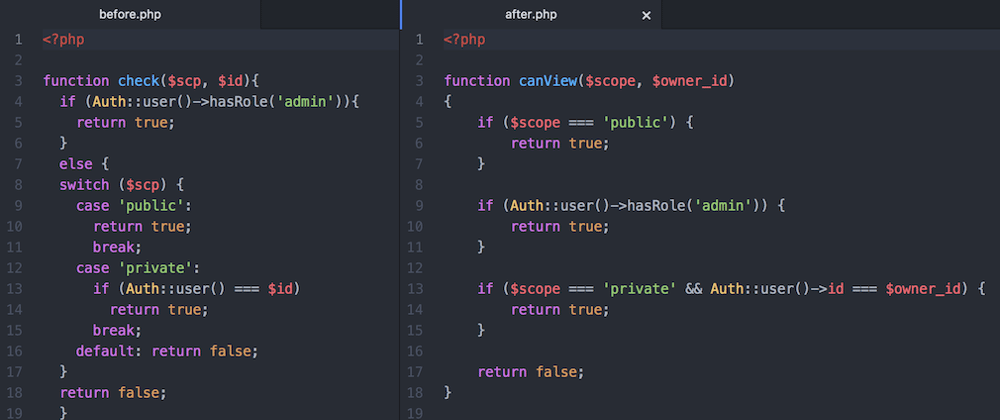
source: Dev Community
Even non-developers can see that the “after” is much easier to read and understand.
Development isn’t just about writing code and calling it a day – it’s about writing quality code.
And that’s the only way to build truly great software.
Excellent software quality should be non-negotiable – no one wants to use buggy, low-quality software.
And that’s where QA and software testing come in.
They ensure your software not only works properly but also meets user expectations.
Neglecting QA can cost you a lot of money.
Here’s a staggering statistic – poor software quality costs U.S. companies $2.42 trillion every year.
So, if you don’t want to become a part of that statistic, you need to invest resources into QA.
And you need to do it from the start of development. Fixing bugs after deployment can be up to 100x more expensive than fixing them at the start of development:
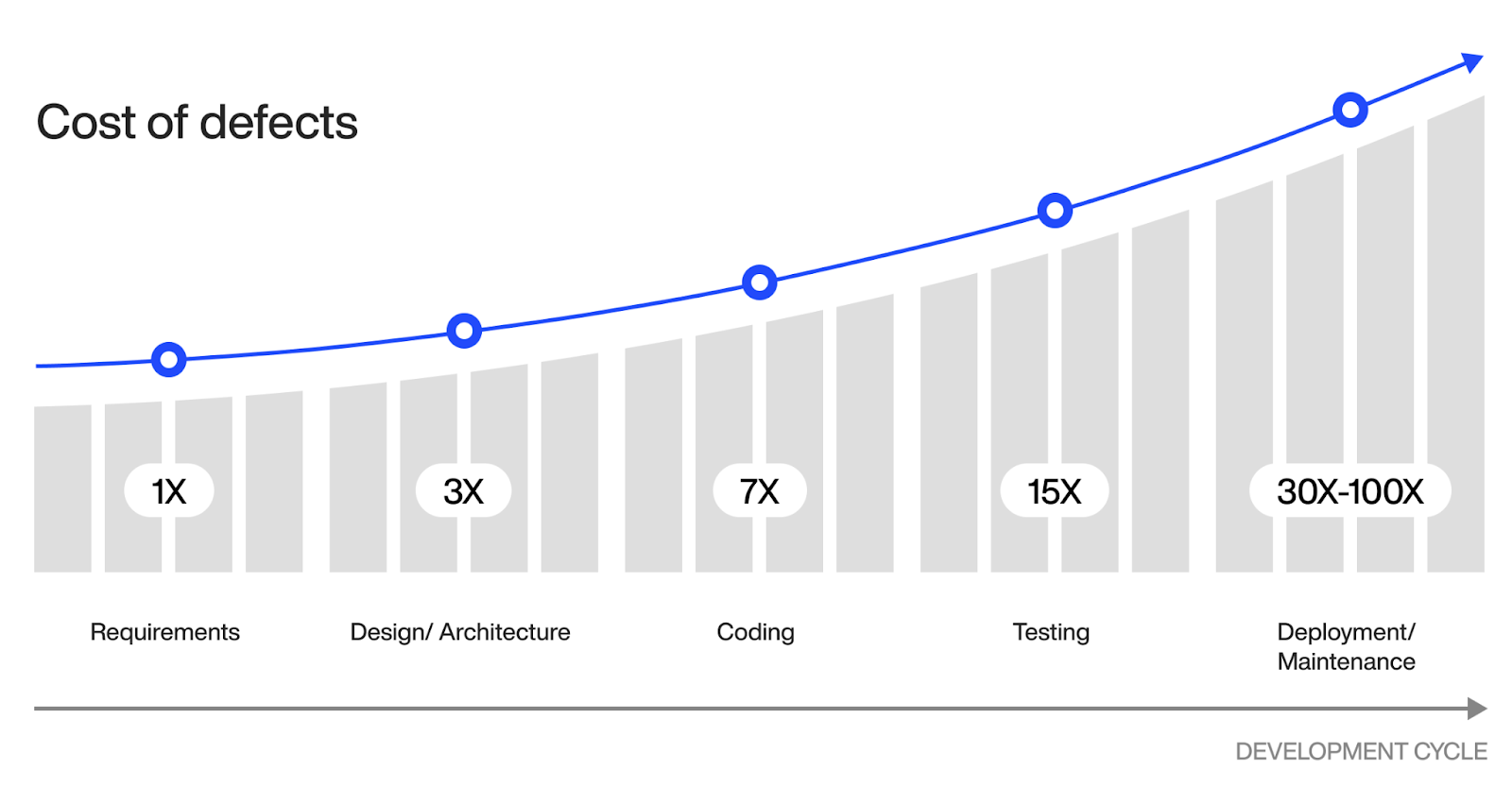
But, to do it right, you need a detailed testing strategy.
This will help your QA engineers better plan tests and choose the right testing methods and metrics to use.
And that’s what you need to build high-quality software.
Deployment is a make-or-break moment in the software development process.
This is where the software moves from development to the live environment and becomes accessible to end users.
And even with flawless code and design, a poorly executed deployment can lead to performance issues, downtime, or even complete system failure.

So, how does it work?
The deployment process involves transferring code to production servers and configuring the necessary infrastructure.
Depending on your project’s complexity, this could be as simple as uploading files or as difficult as coordinating multiple services across cloud platforms.
But, the goal is always the same – a smooth transition with minimal disruption where everything works as intended.
A great way to minimize mistakes, especially when you’re making major updates, is blue-green deployment, where you run two production environments at the same time.
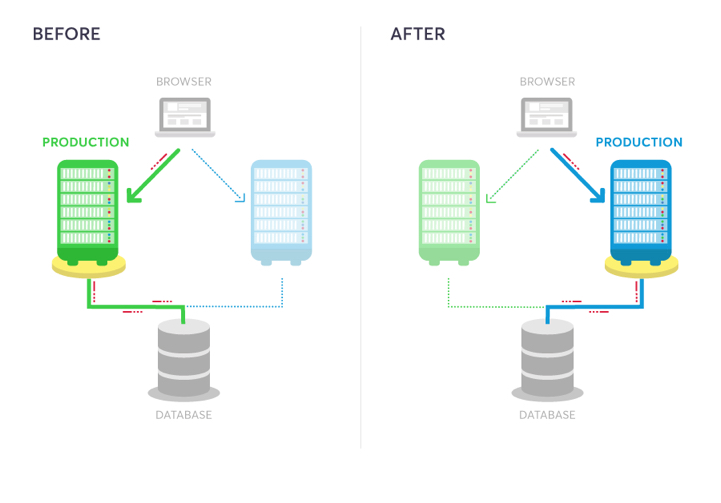
source: AB Tasty
The new version is deployed to one (the “green” environment), while the old version remains live on the other (the “blue” environment).
Once the new version is confirmed to work, traffic is routed to the green environment, and the blue one can be used for rollbacks.
Effective deployment isn’t just about pushing code to production – it’s about delivering reliable, functional software to users without interruption.
Maintenance is the ongoing process of keeping software up-to-date, secure, and fully functional after deployment.
And it shouldn’t be an afterthought.
In fact, over an average software product’s lifetime, maintenance costs add up to over 50% of the total cost of ownership (TCO).
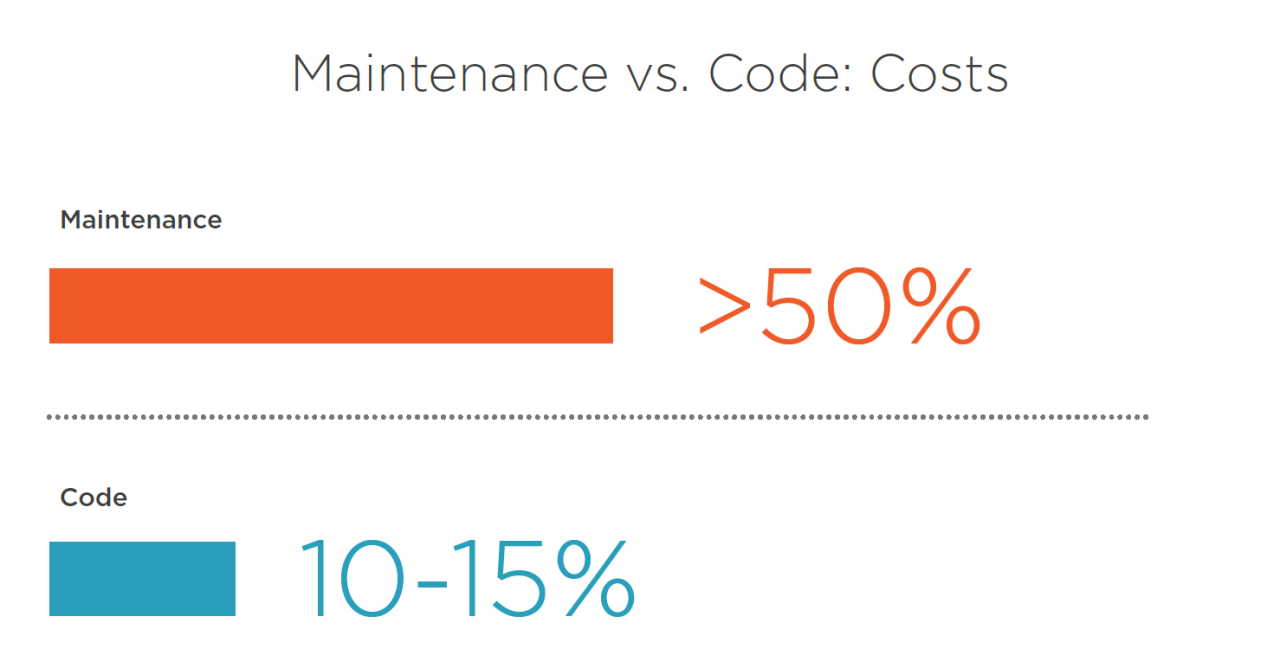
source: LinkedIn
A good rule of thumb is budgeting 15-25% of your initial development budget annually on software maintenance.
So, if your software costs $200,000 to build, you can expect maintenance costs to come out to $30,000-$50,000 per year.
There are 4 types of software maintenance:
Another key aspect of software maintenance is monitoring.
After you deploy your software, you need to continuously track its performance, security, and usage.
This will help you find and fix any issues as soon as they happen.
And that’s key to minimizing disruption.
Next, we’ll cover 5 top software development methodologies you should consider using.
Scrum is a widely-used Agile methodology that emphasizes collaborative work in short, iterative cycles.
And it’s by far the most popular Agile methodology out there, with 81% of Agile teams using Scrum or a Scrum hybrid.
It’s designed for projects that require flexibility, where requirements can change rapidly.
So, how does it work?
Scrum breaks down your software development cycle into smaller (2-4 week) iterations called sprints.
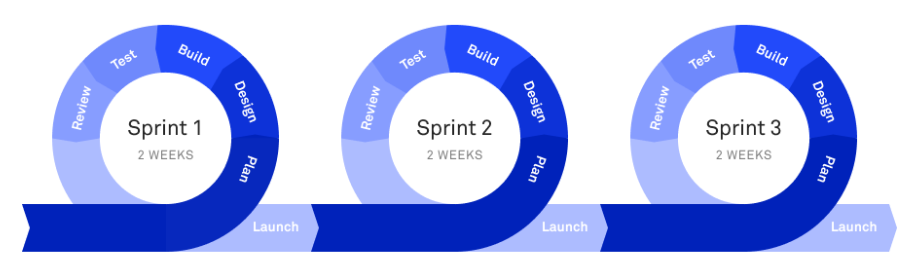
Each sprint is like a mini development cycle, starting with planning all the way through to launch.
And at the end of each sprint, you have a sprint retrospective, where you discuss the previous sprint to find areas for improvement in the next sprint.
“In the first few sprints, you want to get the feel of what your team is capable of doing. After that, you’ll be able to assign tasks per sprint more accurately.”
Marko Strizic, DECODE co-founder and CEO
Scrum is the best fit for smaller teams (3-9 members) and dynamic projects with changing requirements.
And it’s a great choice if you need to get development done faster.
Kanban is an Agile visual workflow management methodology that helps development teams maximize efficiency and productivity.
And it’s effective, too.
87% of teams that use Kanban say that it’s more effective than development methodologies they used previously.
At the heart of Kanban is the Kanban board.
Each column represents a different stage in the workflow and individual tasks are represented by cards that move through the stages.
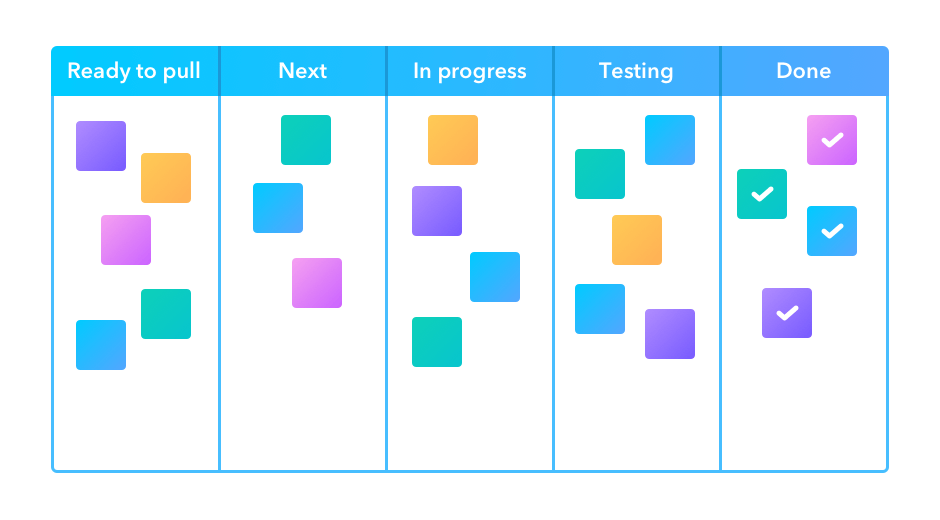
source: Infinity
Kanban’s major strength is its adaptability, as you can use it to easily manage both planned and unplanned tasks.
It’s also ideal for ongoing, long-term projects with a continuous flow of work without a fixed deadline.
Extreme Programming (XP) is an Agile methodology focused on improving software quality and responsiveness to changing project requirements.
XP emphasizes close collaboration between developers and customers, frequent releases, and a high standard of code quality.
It focuses on quick iterations and short development cycles while avoiding excessive documentation.
And what makes that possible are the intense feedback loops at the heart of XP.
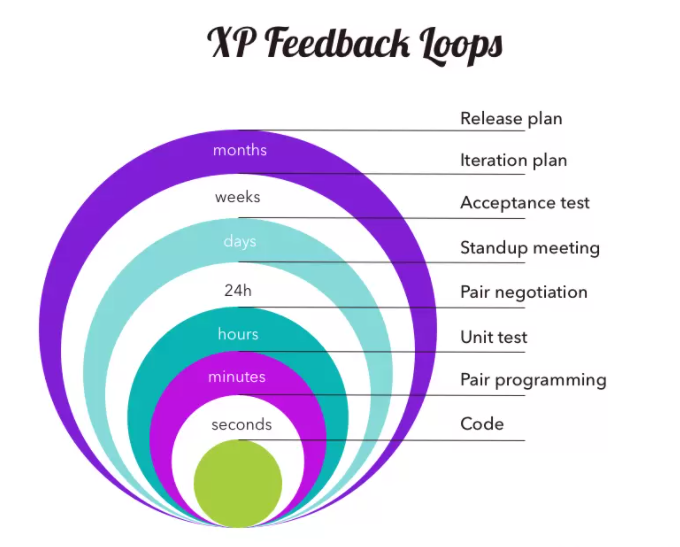
source: AltexSoft
If you have a small team and are working on a high-risk project with unclear or rapidly changing requirements, XP is a great fit.
A good example is if you’re a startup building a minimum viable product (MVP) and refining your product-market fit.
Waterfall is a traditional development methodology that follows a linear, sequential approach to software development.
It has several distinct phases, each representing a step in the development process, from gathering requirements to final project delivery.
And each phase has to be completed before the next phase can begin, so it only goes in one direction – hence, the name waterfall.
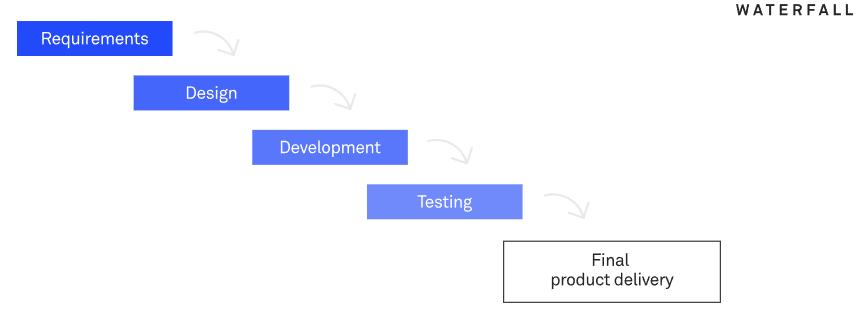
Waterfall is one of the oldest and most structured methodologies, often used in projects with clearly defined requirements and predictable outcomes.
And while it’s outdated and largely replaced by Agile methodologies, it still has a place if you’re building complex, legally-restrictive software where you need to follow a bunch of different procedures and protocols.
The V-model, also known as the validation and verification model, is an extension of the waterfall methodology that emphasizes the importance of testing.
In the V-model, each phase of development has a corresponding testing phase, represented in a “V” shape.
Here’s what that looks like:
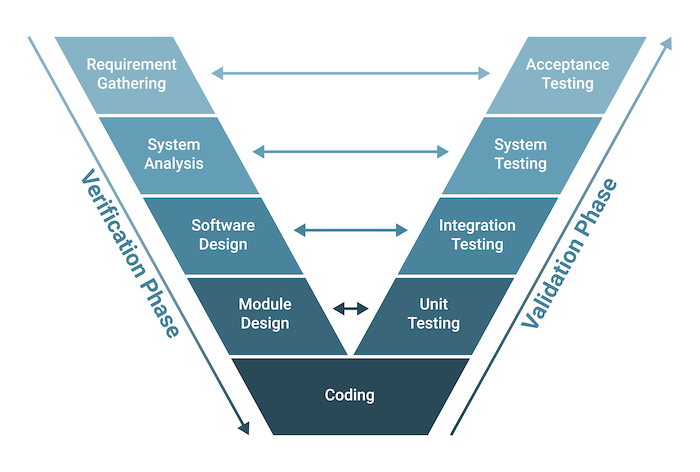
source: Built In
One of the key strengths of the V-Model is its focus on early detection of bugs and defects.
Since testing is planned for each development stage, it allows for validation at every level.
And that’s why it’s a great fit for complex, mission-critical software in highly regulated industries.
Finally, we’ll cover some crucial software development tools you need to know about.
Integrated development environments (IDEs) are software tools that offer everything you need for coding and software development in one place.
They combine several functions, like:
IDEs help developers write, test, and optimize code faster and with fewer errors.
Here are some of the top IDEs on the market today:
So, picking the right IDE and using its full set of features will help you build more reliable software, faster.
And that’s key to successful development.
Build tools in software development automate processes like code compilation, running tests, packaging applications, and dependency management.
Automating these steps helps developers avoid repetitive tasks, reduces errors, and speeds up development.
Here are some build tools you should consider using:
In short, build tools are crucial if you want efficient development.
Choosing the right ones will help you significantly reduce development time and improve code quality.
And that’s exactly what you should want.
Continuous integration (CI) and Continuous delivery (CD) tools are a key part of modern software development.
They help teams automate code integration, testing, and deployment.
This means that new code is consistently integrated into the main codebase, tested, and deployed without the need for manual intervention.
Here are some of the top CI/CD tools on the market:
Also, CI/CD tools help you build software faster – organizations that have mastered it deploy 208 times more often and have a 106 times faster lead time.
And that’s why they’re so vital.
Version control tools help teams track code changes and maintain the integrity of their codebase.
These tools allow developers to manage changes to source code over time and provide a clear history of modifications, so if anything goes wrong, they can easily roll back any changes made.
Here are some version control tools you should know about:
In short, version control tools are the backbone of modern software development.
And they’re key to maintaining high code quality.
Software testing tools ensure the quality, functionality, and security of any piece of software.
They help you find and fix bugs and make sure the software you’re building meets the required specifications.
Some of the most widely used testing tools include:
In a nutshell, without software testing tools, you can’t fix bugs and problems or build high-quality software.
And that’s why they’re so important.
Project management tools are used to organize, track, and deliver software development projects efficiently.
They help teams efficiently manage:
This ensures projects are completed on time, within scope, and within budget.
Some of the top project management tools on the market are:
Project management tools help you organize and improve your development process and keep everyone on the same page.
And that’s why they’re indispensable.
The key steps in a typical software development process are:
The most important step in any software development process is requirements gathering.
Requirements define what your software should do, how it will do it, and how it can meet user and business needs.
Getting them wrong is the number one reason why projects fail, with 37% of software projects failing because of unclear requirements.
And that’s why requirements gathering is the most important step.
Agile development methodologies focus on rapid iteration, quick delivery, and flexibility so they’re more suited to dynamic projects with changing requirements.
On the other hand, waterfall methodologies are more structured and predictable, so they’re better suited to long-term, enterprise-grade projects with stable requirements.
Are you looking for a software development partner but you’ve been burned by terrible vendors before?
Luckily, you’re in the right place.
We’re a full-service, high-caliber software development company building software and we pride ourselves on our quality-first approach.
If you want to learn more, feel free to reach out and we’ll set up a quick meet to discuss how we can help you with your project.

An Applied Sciences graduate and a true connoisseur of tech, Ivan is a software developer with a genuine love for exploring new technologies. QAs love his code, and his fellow developers always value his input. For Ivan, there is no issue too small to talk over, and no problem that can’t be solved together. When he is not coding, Ivan is usually hiking or playing football. His ideal workspace? Probably a cottage in the mountains, with a serious gaming setup and fast internet connection.
Here, we cover the 7 key roles you need on your software development team and their responsibilities.

Here, we'll discuss the 8 best software development methodologies out there and how to pick the best one for your project.

What is offshore software development, how does it work, and how do you choose the right partner? A practical 2026 guide covering costs, models, risks, and top destinations.