Shake is DECODE’s sister company. It’s a comprehensive bug and crash reporting tool for mobile apps, built for developers so they can always know the cause of a bug.
It’s used all around the world, and its users rate it on a par with leading Apple and Google products.
Shake is a great example of how our software development process comes together. We came up with the idea, carried out market research, then assembled a team to make it a reality.
This blog will highlight how we developed Shake through prototyping, product development, testing, and ongoing updates. It took 2 years for our team to launch Shake on the market.
Table of Contents
The Team Behind Shake
The Shake team began as just two developers, but this quickly increased to seven.
Developing an innovative software product such as Shake from scratch is a challenge and pleasure at the same time.
A well-organized team with clear leadership and defined processes certainly contributes to the quality of the product.
Meetings
When working for clients, we follow the Scrum methodology, so it was a logical choice to use the same principles for our own software product as well.
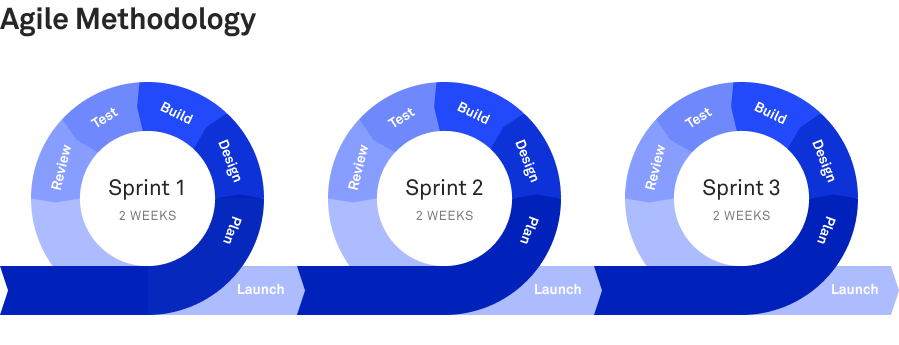
Scrum is an agile development methodology which facilitates adaptive planning, evolutionary development, early delivery, and continual improvement – it also encourages flexible responses to change.
It consists of sprints which are usually 2 weeks long. Every sprint consists of the same phases: Plan, design, build, test and review.
Scrum encourages development teams to hold different types of meetings, and we hold three types; daily standups, sprint planning, and backlog grooming meetings.
Daily Standup Meeting
A short session where team members discuss current progress on assigned tasks. It is also an opportunity to discuss any blockers and mention completed tasks from the previous day.
After this discussion, the Jira board is updated accordingly.
Daily standup meetings usually take up to 15-30 minutes, but can be extended if required and are crucial for team communication.
Sprint Planning Meeting
The main objective is to plan and prepare for the next sprint and to re-estimate rollovers.
Rollovers are the tasks that will not be completed in the current sprint and which therefore need to be included in the next sprint. This meeting is also used for checking reports like burndown charts and velocity reports.
A burndown chart is a graphical representation of work left to do in a timeframe and is useful for predicting when the remaining work will be completed and what will probably end up as a rollover to the following sprint.
Velocity shows the amount of work the team usually completes in a typical time frame.
Sprint planning meetings usually take up to 90 minutes.
Backlog Grooming Meeting
This kind of meeting happens in the middle of the sprint and is used for story point estimating and for the planning of the next 2 sprints.
Discussion is encouraged during this meeting, and it is not focused on sprint that is in progress but rather on planning future sprints, adding discovery tasks, splitting tasks, planning release dates, and tagging tasks with fixed version.
All of this helps prevent a backlog from becoming too large to manage.
At the end of this meeting, the team should have an idea of what the prioritized stories are, and have identified any larger stories that should be fragmented and filled with details for the next sprint.
Backlog grooming meetings usually take up to 120 minutes.
Jira Setup
We have 4 different issue types in Jira.
Epic is a large amount of work that can be fragmented into smaller chunks, called tasks.Epic usually contains a general description of the work needed to be done, while tasks and subtasks contain more specific details.
Epic usually contains a list of tasks that are linked to it, but tasks do not need to have epics assigned.
Subtasks are created during the QA process and are assigned to tasks that require additional work to be done before they can be considered complete.
Bug types are created for the defects reported from the production environment.
Custom Jira fields are added to the issues. The QA field contains the person responsible for the QA of that issue.
The Code reviewer field shows the person responsible for reviewing open pull requests on git for that issue. The Fix version field is used for noting the version in which issue changes have been released to production.
Component represents the platform/part of the product that task relates to (Android, iOS, Flutter, React Native, Homepage, API, Dashboard, Docs).
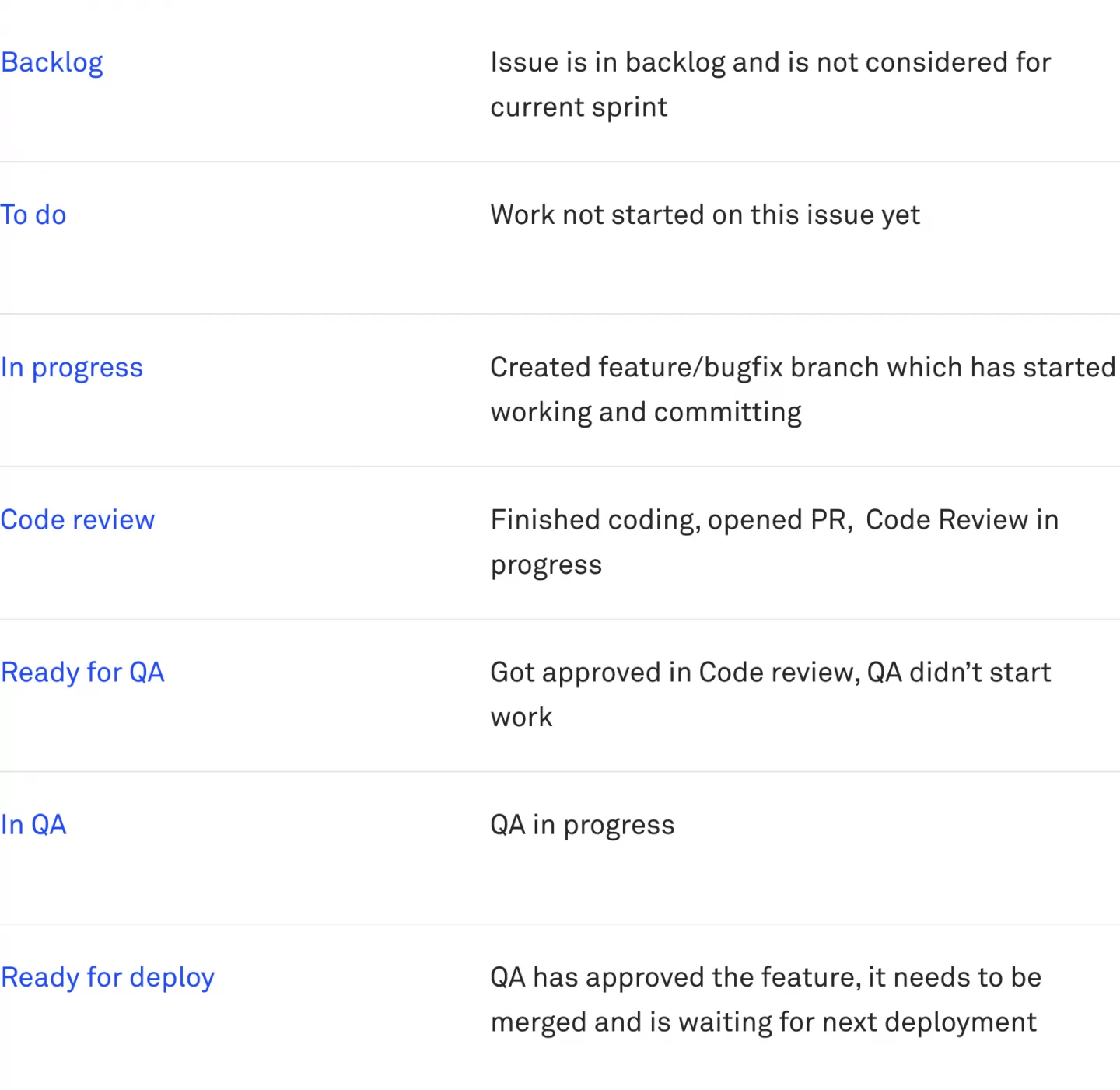
Jira workflow can be described using issues statuses that also have matching columns on the print board:
Putting values into QA’s and Code review issue cards is mandatory. While the issue cards move from “in progress” to “code review” status, Jira creates a pop-up in which the users select values for the given field.
In some common scenarios, automation is also added. For example; subtasks created from tasks automatically inherit common fields from the parent, such as assignee, QA, Fix version, current sprint, etc.
QA
There are three main types of testing for QA:
1. Feature/bugfix testing
Every new feature or bugfix needs to be verified by a QA engineer before being merged into the develop branch.
Here we use the ‘test then merge’ principle. QA engineers will build the app when a pull request opens up, and then manually test the changes
This keeps the develop branch ‘release-ready’ so that the team can decide to release a new version at any point in time, without fear of regressions.
On the other hand, the web part of the project works on the ‘merge than test’ principle. Because of the current size of the QA team, we cannot test everything in real time, but the frontend and backend are easier to maintain because they are more flexible than mobile apps.
This sense, the develop branch is not release-ready at all times, and requires greater attention when releasing new versions due to the danger of regression.
When QA engineers discover bugs or issues in this kind of testing, they won’t open a new task or bug on the Jira board, but will rather create a subtask for the current task.
2. Regression testing
The release branch is created during regression testing. We create tasks for upcoming releases in Jira and do a regression test before every release. Use cases, which are tested in regression testing, are all listed in TestRail.
Regression testing can only be done by a QA engineer. But, if the QA needs help, he/she can assign it to other teammates. Issues found during regression testing are noted in Jira as subtasks of the upcoming release task (which was created earlier for that specific release).
3. Automatic testing
Automated tests are a part of every pipeline/workflow run. We are still creating automated UI tests for the Shake SDK, and the plan is to run UI tests on every PR opened from the develop branch.
On the web, we currently run UI tests on every update which we deploy to staging and production environments.
Code management
We strictly follow GitFlow branching strategy, to which we have added some additional rules due to the specific needs of this project.
GitFlow is a branching model for Git, created by Vincent Driessen. This model allows work in progress to be kept separate from finished work by using feature branches that merge back into the main branch when the code is stable and ready for a new release. It is therefore well-suited for collaboration and the scaling of the development team.
The model also simplifies the management of new releases and is compatible with emergency fixes.
Here is a more detailed list of all branches and branch types used on Shake:
1. develop
our primary branch, used to develop the product needs to be production-ready at all times direct commits are forbidden only branches that have been reviewed, approved, and tested can be merged into the develop branch (feature/, hotfix/, bugfix/* and release/* branches)
2. main
contains the production code of the latest version direct commits are forbidden only branches which have been reviewed, approved, and tested can be merged into the main branch (hotfix/* and release/* branches)
3. feature/.
these branches are used for developing new features they branch out from the develop branch and merge back into it when completed every feature/* branch needs to have a name in this format → feature/SHK-xyz- git squash and rebase has to be done on develop branch before opening a PR after code passes the review, QA engineer will test the new feature in feature/* branch feature/* branch can only be merged after it has both code review approval and QA approval
4. release/.
release/. branches are used for preparing new releases release/* branches are branched out from develop branch or version tags every release/* branch needs to have name in this format → release/x.y.z where x.y.z is version name, e.g. release/2.3.1 you can directly commit to release/* branch while fixing issues found during regression testing. After all the issues found during regression testing are fixed and validated, we can merge this branch. if release/* is branched from develop, we merge into main branch first and then into develop if release/* is branched from a version tag, we merge it into develop only if needed don’t rebase before merging release/* branch
5. hotfix/.
hotfix/. branches are used for fixing urgent bugs (which cannot wait for the next scheduled release) found on the latest production version hotfix/* branches are branched out from the main branch every hotfix/* branch needs to have name in this format →hotfix/x.y.z where x.y.z is version name, e.g. hotfix/2.3.1 you can directly commit to hotfix/* branch while fixing issues found during regression testing. We perform regression testing before releasing a hotfix version, same as for normal release/. After all the issues found in regression testing are fixed and validated, we can merge this branch we merge back to main first, and to develop afterwards again, don’t rebase before merging hotfix/ branch
6. bugfix/.
bugfix/. branches are used for fixing bugs found on production. Bugfixes are not as urgent as hotfixes and they are released in one of the next scheduled releases we branch out from the develop or version tag if we are patching up older versions every bugfix/* branch needs to have name in this format: → bugfix/SHK-xyz- if bugfix is branched from develop, we follow same rules as for feature/* branches if bugfix is branched from a version tag, bugfix/* branch is merged back to release without rebasing and squashing. A QA engineer will test a bugfix in bugfix/* after the code passes the review bugfix/* branch can only be merged after it has both code review approval and QA approval
Code review is done on every PR. Every PR needs to have at least one approval before merging. We are doing PR on every merge into →develop, →main or →release branches.
Release management
A Jira issue is created for every planned release.
Git branch is created and all the required changes are added to it during the development of new features or while fixing reported bugs.
In the QA phase, regression testing is performed on that release. All the issues which are identified will be fixed and applied into that release branch. After that, the release of updated documentation and the actual release of the new code into production is completed.
Every Jira issue has a fix version because of the tracking progress for each release.
Conclusion
For Shake, we delivered the first SDKs for iOS and Android, together with a powerful dashboard. This dashboard is rich with features, such as screen recording, detailed app telemetry and crash reporting. It is also compatible with 3rd party integrations which allows you to connect Shake to Jira, Asana, and Azure DevOps.
For anyone out there starting to develop a software product from scratch, we would recommend this type of setup and delivery process. And if you have any questions, feel free to get in touch with us.
Skilled in React Native, iOS and backend, Toni has a demonstrated knowledge of the information technology and services industry, with plenty of hands-on experience to back it up. He’s also an experienced Cloud engineer in Amazon Web Services (AWS), passionate about leveraging cloud technologies to improve the agility and efficiency of businesses.
One of Toni’s most special traits is his talent for online shopping. In fact, our delivery guy is convinced that ‘Toni Vujević’ is a pseudonym for all DECODErs.
There are different ways to create your Views: the good old option of creating them programmatically, using XIBs, or the latest Apple-provided format, Storyboard. There’s quite a lot of discord over what the best method is, and there is no universal answer.
Apparently, millennials are getting sick and tired of the carefully manicured social media profiles and are looking to shake things up. Make them more authentic, so to speak.
The media has long been looking for ways to disrupt the industry, and they’ve tried on just about every channel there is: You can get your news via short videos on Instagram, as disappearing snaps on Snapchat or even via Viber.